
Série: Distribuições de Probabilidade
Esta é a primeira postagem de uma série sobre as principais distribuições de probabilidade usadas em Estatística. Começamos pela mais famosa: a distribuição normal, também chamada de distribuição de Gauss ou curva em sino.
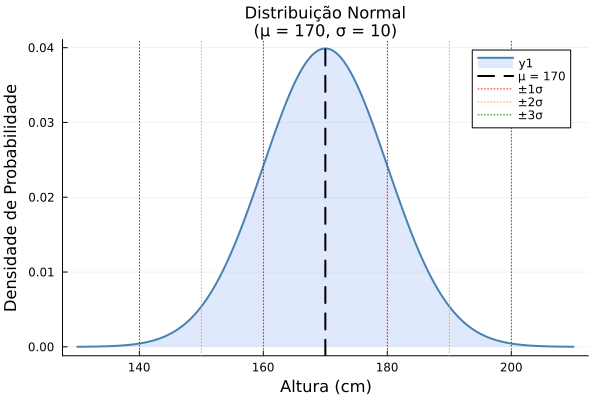
O que é a distribuição normal e por que ela é tão importante?
Poucas ideias na história da ciência se mostraram tão úteis quanto a distribuição normal. Ela aparece na altura de uma população, no erro de medição de instrumentos de precisão, no retorno de ativos financeiros, na distribuição de notas de uma prova, na média de tempos de processos industriais. É difícil listar áreas que não a utilizam.
O motivo não é mágica — é matemático. Em sua forma clássica, o Teorema Central do Limite afirma que a média de muitas variáveis aleatórias independentes e identicamente distribuídas, com média e variância finitas, tende a se comportar aproximadamente como uma normal quando o tamanho da amostra cresce. Em outras palavras, a normalidade surge naturalmente sempre que muitos fatores independentes de mesma natureza se combinam — desde que cada um tenha variabilidade limitada.
Uma breve história
A curva em sino tem origem em pelo menos três pensadores do século XVIII e XIX.
Abraham de Moivre (1733) foi o primeiro a descrever matematicamente o que hoje chamamos de distribuição normal, ao estudar a aproximação da distribuição binomial para grandes amostras.
Pierre-Simon Laplace (1812) generalizou e formalizou a ideia, tornando-a central na teoria da probabilidade e nos métodos de estimação.
Carl Friedrich Gauss (1809) a utilizou para modelar os erros de observação em medições astronômicas, tornando o nome distribuição de Gauss sinônimo da curva. É por isso que ela carrega o nome dele, embora De Moivre e Laplace tenham contribuições anteriores igualmente essenciais.
Fórmula da distribuição normal
A função de densidade de probabilidade (FDP) da distribuição normal é:
\[f(x) = \frac{1}{\sigma\sqrt{2\pi}} \, e^{-\frac{1}{2}\left(\frac{x - \mu}{\sigma}\right)^2}\]Cada elemento desta equação tem um papel:
| Símbolo | Nome | O que faz |
|---|---|---|
| $\mu$ | Média | Define o centro (pico) da curva |
| $\sigma$ | Desvio padrão | Controla a “abertura”: maior $\sigma$, curva mais achatada |
| $\sigma^2$ | Variância | Medida de dispersão ao quadrado |
| $e$ | Base do logaritmo natural ($\approx 2{,}718$) | Cria o decaimento exponencial |
| $\frac{1}{\sigma\sqrt{2\pi}}$ | Coeficiente de normalização | Garante que a área total sob a curva seja igual a 1 |
Escreve-se $X \sim N(\mu, \sigma^2)$ para indicar que a variável $X$ segue uma distribuição normal com média $\mu$ e variância $\sigma^2$.
O que a fórmula realmente está dizendo?
Apesar da aparência intimidante, a fórmula tem uma lógica visual simples:
- $\mu$ move a curva para a esquerda ou para a direita, sem alterar sua forma.
- $\sigma$ controla o espalhamento: um desvio padrão maior achata e alarga a curva; um menor a torna mais estreita e alta.
- O termo exponencial $e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}$ faz a curva cair rapidamente à medida que $x$ se afasta da média — quanto mais longe, mais próximo de zero o valor da função.
- O coeficiente $\frac{1}{\sigma\sqrt{2\pi}}$ é um fator de escala que não altera o formato da curva, apenas garante que a área total sob ela seja exatamente 1 (conforme demonstrado na seção sobre a integral gaussiana).
Propriedades fundamentais
1. Simetria
A curva é perfeitamente simétrica em torno da média $\mu$. Isso implica que, para qualquer valor $c > 0$:
\[P(X \le \mu - c) = P(X \ge \mu + c)\]A cauda esquerda é um espelho exato da cauda direita.
2. Média, mediana e moda coincidem
Devido à simetria, os três resumos de posição central são iguais:
\[\text{média} = \text{mediana} = \text{moda} = \mu\]3. A área total é 1
Como toda distribuição de probabilidade para variáveis contínuas, a integral da FDP em todo o eixo real é igual a 1:
\[\int_{-\infty}^{+\infty} f(x)\, dx = 1\]4. As caudas nunca tocam o eixo
A curva se estende indefinidamente nos dois sentidos, aproximando-se do eixo horizontal mas nunca o tocando. A densidade da normal é positiva para qualquer valor real, mas isso não significa que a probabilidade de observar exatamente um valor específico seja positiva. Em distribuições contínuas, probabilidades são calculadas para intervalos, não para pontos isolados: a probabilidade de $X$ assumir exatamente um valor qualquer é sempre zero. O que esta propriedade diz, portanto, é que nenhum intervalo — por mais distante que esteja da média — tem probabilidade absolutamente nula.
A integral gaussiana
A propriedade 3 afirma que a área total sob a curva normal é 1, mas isso não é óbvio — na fórmula aparece a expressão $e^{-x^2}$, cuja primitiva não existe em termos de funções elementares. Não há como calcular essa integral pelo caminho usual de encontrar uma antiderivada e aplicar o Teorema Fundamental do Cálculo.
A saída elegante foi descoberta por Laplace e consiste em calcular o quadrado da integral usando coordenadas polares. Abaixo está o cálculo completo, passo a passo.
Passo 1 — definir a integral
Defina:
\[I = \int_{-\infty}^{+\infty} e^{-x^2}\, dx\]O objetivo é provar que $I = \sqrt{\pi}$. Como $e^{-x^2} > 0$ para todo $x$, sabe-se que $I > 0$.
Passo 2 — elevar ao quadrado e transformar em integral dupla
Como $I$ é um número real positivo, vale:
\[I^2 = \left(\int_{-\infty}^{+\infty} e^{-x^2}\, dx\right)\left(\int_{-\infty}^{+\infty} e^{-y^2}\, dy\right)\]As duas integrais têm variáveis independentes ($x$ e $y$), então podem ser reunidas em uma única integral dupla sobre o plano inteiro:
\[I^2 = \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} e^{-(x^2 + y^2)}\, dx\, dy\]Passo 3 — mudar para coordenadas polares
Faça a substituição $x = r\cos\theta$, $y = r\sin\theta$, com $r \ge 0$ e $0 \le \theta < 2\pi$. O elemento de área transforma-se:
\[dx\, dy = r\, dr\, d\theta\]E o expoente fica:
\[x^2 + y^2 = r^2\cos^2\theta + r^2\sin^2\theta = r^2\]A integral dupla torna-se:
\[I^2 = \int_0^{2\pi}\int_0^{+\infty} e^{-r^2}\, r\, dr\, d\theta\]Passo 4 — resolver a integral interna em $r$
Calcule $\displaystyle\int_0^{+\infty} r\, e^{-r^2}\, dr$ por substituição. Faça $u = r^2$, logo $du = 2r\, dr$, ou seja, $r\, dr = \dfrac{du}{2}$. Quando $r = 0$, $u = 0$; quando $r \to +\infty$, $u \to +\infty$:
\[\int_0^{+\infty} r\, e^{-r^2}\, dr = \int_0^{+\infty} e^{-u}\, \frac{du}{2} = \frac{1}{2}\left[-e^{-u}\right]_0^{+\infty}\] \[= \frac{1}{2}\left(\lim_{u \to +\infty}(-e^{-u}) - (-e^{0})\right) = \frac{1}{2}(0 + 1) = \frac{1}{2}\]Passo 5 — resolver a integral externa em $\theta$
A integral interna não depende de $\theta$, então:
\[I^2 = \int_0^{2\pi} \frac{1}{2}\, d\theta = \frac{1}{2} \cdot 2\pi = \pi\]Passo 6 — concluir
Como $I > 0$:
\[I^2 = \pi \implies I = \sqrt{\pi}\]Portanto:
\[\int_{-\infty}^{+\infty} e^{-x^2}\, dx = \sqrt{\pi}\]Passo 7 — provar que a área sob a curva normal é 1
Agora mostre que o coeficiente $\dfrac{1}{\sigma\sqrt{2\pi}}$ na fórmula da distribuição normal é exatamente o que garante a área total igual a 1. Parta da integral:
\[\int_{-\infty}^{+\infty} \frac{1}{\sigma\sqrt{2\pi}}\, e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}\, dx\]Substituição 1: faça $u = \dfrac{x - \mu}{\sigma}$, logo $x = \mu + \sigma u$ e $dx = \sigma\, du$. Os limites de integração não mudam (de $-\infty$ a $+\infty$):
\[= \frac{1}{\sigma\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-\frac{u^2}{2}}\, \sigma\, du = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-\frac{u^2}{2}}\, du\]Substituição 2: faça $t = \dfrac{u}{\sqrt{2}}$, logo $u = \sqrt{2}\, t$ e $du = \sqrt{2}\, dt$:
\[= \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-t^2}\, \sqrt{2}\, dt = \frac{\sqrt{2}}{\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-t^2}\, dt\]Aplicando o resultado do Passo 6 ($\int_{-\infty}^{+\infty} e^{-t^2}\, dt = \sqrt{\pi}$):
\[= \frac{\sqrt{2}}{\sqrt{2\pi}} \cdot \sqrt{\pi} = \frac{\sqrt{2} \cdot \sqrt{\pi}}{\sqrt{2} \cdot \sqrt{\pi}} = 1\]Isso demonstra que o coeficiente $\dfrac{1}{\sigma\sqrt{2\pi}}$ não é arbitrário — ele é o recíproco exato do valor da integral gaussiana generalizada, e sua única função é garantir que a área total sob a curva seja igual a 1, condição obrigatória para que $f(x)$ seja uma função de densidade de probabilidade válida.
A regra 68–95–99,7
Uma das propriedades mais usadas da distribuição normal é a chamada regra empírica (ou regra 68-95-99,7). Ela descreve quanto da probabilidade está concentrada em torno da média:
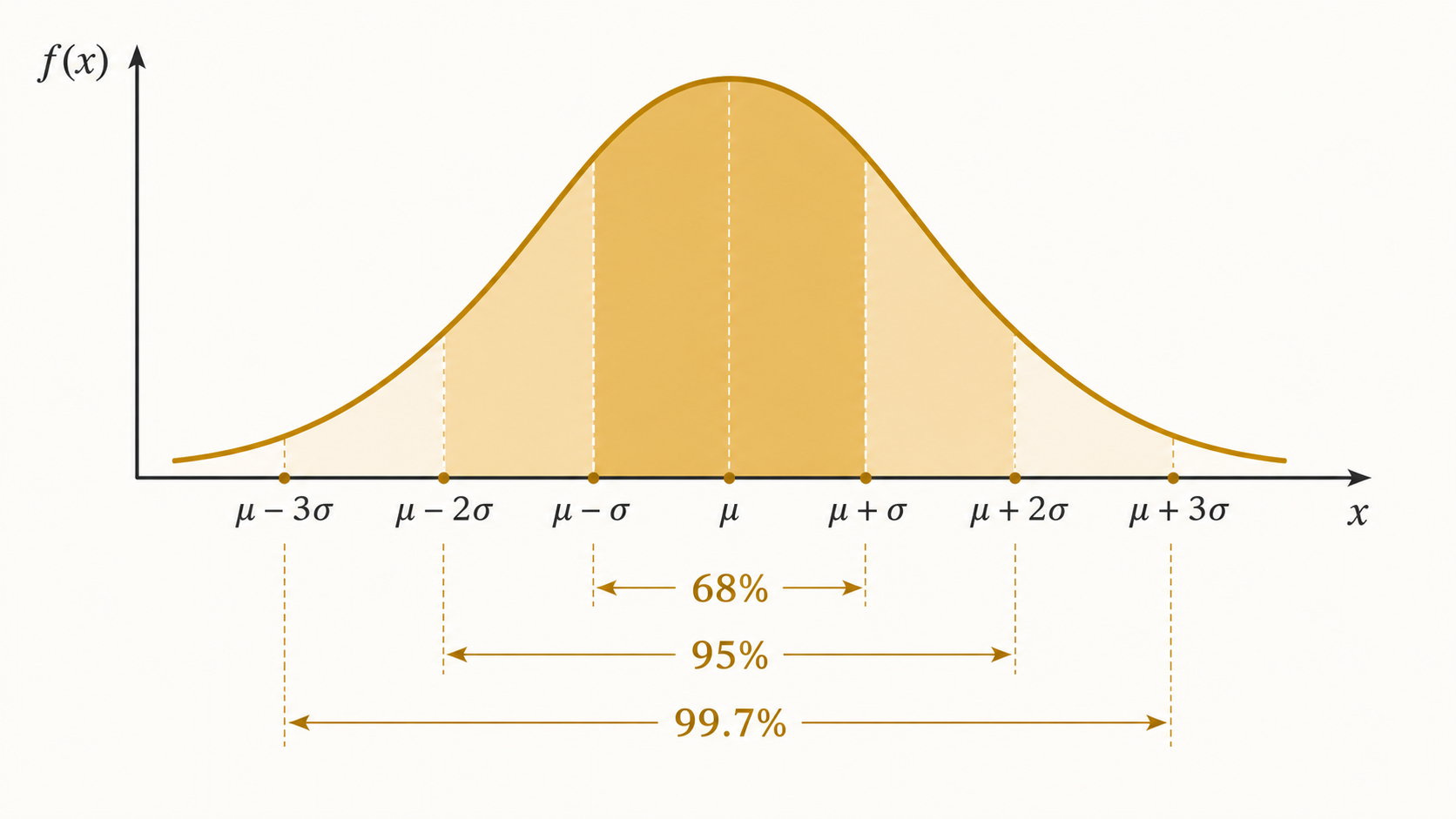
Traduzindo em linguagem direta:
- 68% dos valores ficam a menos de 1 desvio padrão da média.
- 95% dos valores ficam a menos de 2 desvios padrão da média.
- 99,7% dos valores ficam a menos de 3 desvios padrão da média.
Um valor que cai além de 3 desvios padrão da média é raro: acontece em apenas 0,3% dos casos.
Atenção
A regra 68–95–99,7 vale exatamente para distribuições normais. Em dados apenas "parecidos com sino" — especialmente com caudas mais pesadas do que a normal prevê — as porcentagens reais podem diferir significativamente. Use a regra com cautela em distribuições assimétricas ou com assimetria nas caudas.
Como calcular probabilidade usando o escore Z
Quando $\mu = 0$ e $\sigma = 1$, obtemos a distribuição normal padrão, denotada $Z \sim N(0, 1)$. Sua FDP simplifica para:
\[\phi(z) = \frac{1}{\sqrt{2\pi}} \, e^{-\frac{z^2}{2}}\]Qualquer variável $X \sim N(\mu, \sigma^2)$ pode ser padronizada pela transformação:
\[Z = \frac{X - \mu}{\sigma}\]O valor $Z$ resultante — o escore Z — indica quantos desvios padrão o valor $X$ está acima ou abaixo da média. Essa transformação é fundamental porque permite consultar uma única tabela (a tabela Z) para calcular probabilidades de qualquer distribuição normal, independentemente de $\mu$ e $\sigma$.
Como usar a distribuição normal na prática
Antes de partir para os exemplos, vale ter claro o fluxo de trabalho padrão:
- Identifique $\mu$ e $\sigma$ a partir do enunciado do problema.
- Transforme o valor observado em escore Z pela fórmula $Z = \dfrac{x - \mu}{\sigma}$.
- Consulte a tabela Z para encontrar $P(Z \le z)$.
- Use complemento ou diferença de áreas quando precisar de probabilidades de caudas opostas ou de intervalos.
- Interprete o resultado como probabilidade de intervalo, nunca como probabilidade de um ponto exato.
Exemplos resolvidos de distribuição normal
Exemplo 1: probabilidade em uma distribuição normal qualquer
Suponha que as notas de uma turma sigam $X \sim N(70, 100)$, ou seja, média $\mu = 70$ e variância $\sigma^2 = 100$ (portanto $\sigma = 10$).
Pergunta: qual é a probabilidade de um aluno tirar nota menor que 85?
Passo 1: padronize o valor $x = 85$:
\[Z = \frac{85 - 70}{10} = \frac{15}{10} = 1{,}5\]Passo 2: consulte a tabela Z para $z = 1{,}5$:
\[P(Z \le 1{,}5) \approx 0{,}9332\]Conclusão: há aproximadamente 93,32% de chance de um aluno tirar nota menor que 85.
Exemplo 2: probabilidade entre dois valores
Usando os mesmos parâmetros ($\mu = 70$, $\sigma = 10$), qual é a probabilidade de a nota ficar entre 60 e 80?
Passo 1: padronize os dois limites:
\[Z_1 = \frac{60 - 70}{10} = -1{,}0 \qquad Z_2 = \frac{80 - 70}{10} = 1{,}0\]Passo 2: calcule a probabilidade entre $-1$ e $1$ pela tabela Z:
\[P(-1 \le Z \le 1) = P(Z \le 1) - P(Z \le -1)\] \[= 0{,}8413 - 0{,}1587 = 0{,}6826\]Conclusão: há 68,26% de chance de a nota ficar entre 60 e 80 — exatamente o intervalo de $\pm 1\sigma$ previsto pela regra empírica.
Exemplo 3: encontrar o valor correspondente a uma probabilidade
Ainda com $X \sim N(70, 100)$: qual nota $x$ é ultrapassada por apenas 10% dos alunos? Em outras palavras, qual é o percentil 90?
Passo 1: na tabela Z, encontre o valor $z$ tal que $P(Z \le z) = 0{,}90$:
\[z \approx 1{,}28\]Passo 2: desfaça a padronização para recuperar $x$:
\[x = \mu + z \cdot \sigma = 70 + 1{,}28 \cdot 10 = 70 + 12{,}8 = 82{,}8\]Conclusão: o percentil 90 da distribuição é 82,8. Apenas 10% dos alunos tiram nota acima de 82,8.
Quando não usar a distribuição normal
A distribuição normal é poderosa, mas não universal. Ela não é adequada quando:
- Os dados são assimétricos, como renda ou preços de imóveis — situações onde a distribuição log-normal ou exponencial pode ser mais indicada. Note que tempos individuais de espera também costumam ser assimétricos e são mais bem modelados por distribuições como exponencial, gama ou log-normal; já médias de muitos tempos de espera podem se aproximar da normal por efeito do Teorema Central do Limite.
- Os valores são restritos a um intervalo, como proporções entre 0 e 1 — onde a distribuição beta é mais natural.
- Eventos raros de contagem são modelados — onde a distribuição de Poisson é mais apropriada.
- As caudas são pesadas, como em retornos financeiros extremos — onde distribuições com caudas mais grossas (como a t de Student) representam melhor a realidade.
Reconhecer quando a normalidade é uma boa aproximação — e quando ela falha — é parte central do trabalho estatístico.
Próxima postagem da série
Na próxima postagem, exploraremos a distribuição de Poisson, que modela a contagem de eventos raros em um intervalo fixo de tempo ou espaço — com uma estrutura matemática completamente diferente da normal, mas com aplicações igualmente amplas.
Referências
- De Moivre, Abraham. The Doctrine of Chances. 2. ed. Londres, 1738.
- Laplace, Pierre-Simon. Théorie Analytique des Probabilités. Paris: Courcier, 1812.
- Gauss, Carl Friedrich. Theoria Motus Corporum Coelestium. Hamburgo: Perthes & Besser, 1809.
- Casella, George; Berger, Roger L. Statistical Inference. 2. ed. Duxbury Press, 2002.
- Stigler, Stephen M. The History of Statistics: The Measurement of Uncertainty before 1900. Harvard University Press, 1986.

Comentários