
1. Quarteto de Anscombe: quatro gráficos, quase os mesmos números
O Quarteto de Anscombe é um dos exemplos mais famosos da Estatística porque mostra uma lição simples e poderosa:
estatísticas resumidas podem ser iguais, mas os gráficos podem contar histórias completamente diferentes.
Ele é formado por quatro conjuntos de dados. Cada conjunto possui pares de valores $(x, y)$. Quando calculamos média, variância, correlação de Pearson e reta de regressão, os resultados são praticamente os mesmos. Porém, quando fazemos os gráficos de dispersão, percebemos que os padrões são muito diferentes.
Se média, variância, correlação e reta de regressão são quase iguais, por que os gráficos são tão diferentes?
A resposta é que uma única estatística raramente consegue representar toda a estrutura dos dados. Ela resume. E todo resumo, por definição, perde informação.
2. O que é o Quarteto de Anscombe?
O Quarteto de Anscombe foi apresentado pelo estatístico Francis J. Anscombe no artigo Graphs in Statistical Analysis, publicado em 1973 na revista The American Statistician.
A ideia do exemplo é didática: mostrar que gráficos não são apenas enfeites em uma análise estatística. Eles são parte essencial da investigação dos dados.
O que os números sugerem?
Os quatro conjuntos parecem quase iguais quando observamos apenas estatísticas resumidas.
Média, variância, correlação e regressão apontam para uma relação parecida.
O que os gráficos revelam?
Os quatro conjuntos têm padrões visuais diferentes.
Há linearidade, curvatura, pontos influentes e concentração artificial de valores.
Em forma compacta:
\[\text{mesmos resumos estatísticos} \not\Rightarrow \text{mesma estrutura dos dados}\]O Quarteto de Anscombe mostra que uma análise estatística responsável deve combinar resumos numéricos com visualização de dados.
3. Os dados do Quarteto de Anscombe
Cada conjunto possui 11 observações. Os três primeiros usam os mesmos valores de $x$. O quarto conjunto possui quase todos os valores de $x$ iguais a 8, com um ponto distante em $x = 19$.
| Conjunto | Característica visual | O que pode enganar? |
|---|---|---|
| I | Relação aproximadamente linear | Este é o caso em que a reta resume razoavelmente bem o padrão |
| II | Padrão curvo | A correlação linear ignora a curvatura |
| III | Quase linear, mas com um ponto discrepante | Um único ponto altera a reta e a correlação |
| IV | Quase todos os valores de $x$ são iguais | Um ponto com $x$ distante domina a regressão |
O ponto mais importante é que a tabela acima só fica clara depois que olhamos os gráficos.
4. O paradoxo didático: números parecidos, histórias diferentes
Os quatro conjuntos possuem aproximadamente:
Uma forma simples de resumir a situação é:
Mesmo assim, os gráficos são muito diferentes.
Quando usamos apenas média, variância, correlação e regressão, podemos perder informações importantes sobre curvatura, assimetria, agrupamentos e pontos influentes.
5. Resumos estatísticos dos quatro conjuntos
Usando o código em Julia deste post, obtemos os seguintes resultados aproximados:
| Conjunto | $\bar{x}$ | $\bar{y}$ | $s_x^2$ | $s_y^2$ | $r$ | Reta ajustada |
|---|---|---|---|---|---|---|
| I | 9,0000 | 7,5009 | 11,0000 | 4,1273 | 0,8164 | $\hat{y} = 3{,}0001 + 0{,}5001x$ |
| II | 9,0000 | 7,5009 | 11,0000 | 4,1276 | 0,8162 | $\hat{y} = 3{,}0009 + 0{,}5000x$ |
| III | 9,0000 | 7,5000 | 11,0000 | 4,1226 | 0,8163 | $\hat{y} = 3{,}0025 + 0{,}4997x$ |
| IV | 9,0000 | 7,5009 | 11,0000 | 4,1232 | 0,8165 | $\hat{y} = 3{,}0017 + 0{,}4999x$ |
Observe como os números são parecidos. Se uma pessoa analisasse apenas essa tabela, talvez dissesse:
os quatro conjuntos apresentam uma relação linear positiva moderada a forte entre $x$ e $y$.
Mas essa interpretação seria incompleta.
6. Como cada gráfico muda a interpretação?
Conjunto I: relação aproximadamente linear
O primeiro conjunto é o mais comportado. A nuvem de pontos segue uma tendência aproximadamente linear. Nesse caso, a reta de regressão é uma descrição razoável do padrão geral.
Aqui, a correlação e a reta de regressão contam uma história compatível com o gráfico.
Conjunto II: relação curva
O segundo conjunto tem uma estrutura curvilínea. A correlação de Pearson ainda aparece alta, mas ela mede associação linear. Portanto, ela não descreve bem a curvatura dos dados.
A relação entre $x$ e $y$ existe, mas não parece linear. Uma reta pode ser uma simplificação ruim.
Conjunto III: ponto discrepante com grande influência
O terceiro conjunto parece ter uma tendência linear, mas um ponto muito alto em $y$ influencia o ajuste da reta.
Um único ponto pode afetar fortemente a correlação e a regressão. Por isso, é importante investigar pontos influentes.
Conjunto IV: ponto de alavancagem
O quarto conjunto possui quase todos os valores de $x$ iguais a 8. A reta é praticamente determinada por um único ponto distante em $x$.
Mesmo com correlação alta, o gráfico mostra que a relação depende demais de uma observação com alta alavancagem.
O Quarteto de Anscombe ensina que correlação e regressão devem ser interpretadas junto com gráficos de dispersão, e não como substitutas da visualização.
7. Correlação de Pearson: o que ela mede e o que ela não mede
A correlação de Pearson mede a força e a direção de uma associação linear entre duas variáveis quantitativas.
A fórmula é:
Quando $r$ está próximo de 1, existe uma associação linear positiva forte. Quando $r$ está próximo de -1, existe uma associação linear negativa forte. Quando $r$ está próximo de 0, não há forte associação linear.
Mas isso não significa que não exista relação alguma.
O que a correlação capta bem?
Associações aproximadamente lineares.
Direção geral da relação entre duas variáveis.
O que a correlação pode esconder?
Curvaturas, agrupamentos, pontos influentes e relações não lineares.
Ela também não prova causalidade.
Ver uma correlação alta e concluir imediatamente que a relação é linear, estável e causal. O gráfico precisa ser analisado antes dessa conclusão.
8. Regressão linear: por que a mesma reta pode enganar?
A regressão linear simples ajusta uma reta do tipo:
No Quarteto de Anscombe, os quatro conjuntos produzem aproximadamente a mesma reta:
\[\hat{y} \approx 3 + 0{,}5x\]A inclinação $0{,}5$ sugere que, para cada aumento de uma unidade em $x$, o valor previsto de $y$ aumenta, em média, cerca de meia unidade.
Mas essa interpretação só é segura quando o modelo linear é uma descrição razoável dos dados.
Antes de confiar em uma regressão linear, observe o gráfico de dispersão e os resíduos. A reta pode existir matematicamente, mas não representar bem a estrutura real dos dados.
9. Código em Julia com CairoMakie
O código abaixo monta os dados do Quarteto de Anscombe, calcula as estatísticas principais, ajusta a reta de regressão, constrói intervalos de confiança pontuais e gera uma figura 2 × 2 com CairoMakie.
Para instalar os pacotes necessários, execute no REPL do Julia:
using Pkg
Pkg.add(["CairoMakie", "Distributions"])Agora, o script completo:
# ============================================================
# Quarteto de Anscombe em Julia — CairoMakie
# Equivalente ao script R do vídeo (ggplot2 + stat_cor)
# Pacotes: Statistics (stdlib), CairoMakie, Distributions
# ============================================================
#
# Para instalar as dependências, execute no REPL:
# using Pkg
# Pkg.add(["CairoMakie", "Distributions"])
#
# ============================================================
using Statistics
using Distributions # quantil t de Student
using CairoMakie
# ----------------------------------------------------------
# 1. Dados — equivalente a datasets::anscombe do R
# ----------------------------------------------------------
anscombe = (
x1 = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5],
y1 = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68],
x2 = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5],
y2 = [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74],
x3 = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5],
y3 = [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73],
x4 = [8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8],
y4 = [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89],
)
# ----------------------------------------------------------
# 2. Funções auxiliares
# ----------------------------------------------------------
"""Correlação de Pearson — equivalente a cor(..., method="pearson")"""
function pearson_r(x::AbstractVector, y::AbstractVector)
mx, my = mean(x), mean(y)
num = sum((x .- mx) .* (y .- my))
den = sqrt(sum((x .- mx) .^ 2) * sum((y .- my) .^ 2))
return num / den
end
"""Regressão linear simples — equivalente a lm(y ~ x)"""
function lin_reg(x::AbstractVector, y::AbstractVector)
mx, my = mean(x), mean(y)
slope = sum((x .- mx) .* (y .- my)) / sum((x .- mx) .^ 2)
intercept = my - slope * mx
return slope, intercept
end
"""
Intervalo de confiança pontual da regressão — equivalente a geom_smooth(se=TRUE).
Retorna (y_hat, ci_lower, ci_upper) para cada ponto em x_new.
Fórmula: ŷ ± t_{α/2, n-2} · σ̂ · √(1/n + (x_new - x̄)² / Σ(xᵢ - x̄)²)
"""
function reg_ci(x::AbstractVector, y::AbstractVector,
x_new::AbstractVector; level::Float64 = 0.95)
n = length(x)
slope, int = lin_reg(x, y)
y_hat_obs = slope .* x .+ int
σ̂² = sum((y .- y_hat_obs) .^ 2) / (n - 2)
σ̂ = sqrt(σ̂²)
mx = mean(x)
Sxx = sum((x .- mx) .^ 2)
t_crit = quantile(TDist(n - 2), 1 - (1 - level) / 2)
y_new = slope .* x_new .+ int
se_fit = σ̂ .* sqrt.(1/n .+ (x_new .- mx) .^ 2 ./ Sxx)
return y_new, y_new .- t_crit .* se_fit, y_new .+ t_crit .* se_fit
end
"""Imprime estatísticas descritivas do par (x, y)"""
function print_stats(label::String, x::AbstractVector, y::AbstractVector)
r = pearson_r(x, y)
slope, int = lin_reg(x, y)
println("─── $label ───────────────────────────────")
println(" mean(x) = $(round(mean(x); digits=4))")
println(" mean(y) = $(round(mean(y); digits=4))")
println(" var(x) = $(round(var(x); digits=4))")
println(" var(y) = $(round(var(y); digits=4))")
println(" r Pearson = $(round(r; digits=4))")
println(" y = $(round(slope; digits=4))x + $(round(int; digits=4))")
println()
end
# ----------------------------------------------------------
# 3. Impressão das estatísticas
# ----------------------------------------------------------
println("\n=== Quarteto de Anscombe — Estatísticas Descritivas ===\n")
pares = [(:x1,:y1), (:x2,:y2), (:x3,:y3), (:x4,:y4)]
titulos = ["Exemplo 1", "Exemplo 2", "Exemplo 3", "Exemplo 4"]
for (i, (xk, yk)) in enumerate(pares)
x = getfield(anscombe, xk)
y = getfield(anscombe, yk)
print_stats(titulos[i], x, y)
end
# ----------------------------------------------------------
# 4. Gráficos com CairoMakie
# ----------------------------------------------------------
# Paleta de cores (uma por exemplo)
cores = [
Makie.wong_colors()[1], # azul
Makie.wong_colors()[3], # verde
Makie.wong_colors()[2], # laranja
Makie.wong_colors()[6], # roxo
]
# Figura com layout 2×2
fig = Figure(size = (860, 700), fontsize = 13)
Label(fig[0, 1:2],
"Quarteto de Anscombe",
fontsize = 16,
font = :bold,
padding = (0, 0, 4, 0),
)
positions = [(1,1), (1,2), (2,1), (2,2)]
for (i, (xk, yk)) in enumerate(pares)
x = Float64.(getfield(anscombe, xk))
y = Float64.(getfield(anscombe, yk))
r = pearson_r(x, y)
slope, intcept = lin_reg(x, y)
x_seq = collect(range(minimum(x) - 1, maximum(x) + 1; length = 200))
y_seq, ci_lo, ci_hi = reg_ci(x, y, x_seq)
row, col = positions[i]
ax = Axis(fig[row, col];
title = "$(titulos[i]) r = $(round(r; digits=3))",
titlesize = 13,
titlefont = :bold,
xlabel = "x",
ylabel = "y",
xgridcolor = (:black, 0.08),
ygridcolor = (:black, 0.08),
spinewidth = 0.8,
)
# Sombreamento do IC 95% — equivalente a geom_smooth(se = TRUE)
band!(ax, x_seq, ci_lo, ci_hi;
color = (cores[i], 0.18),
)
# Linha de regressão — equivalente a geom_smooth(method = "lm")
lines!(ax, x_seq, y_seq;
color = (:gray40, 0.85),
linewidth = 1.8,
linestyle = :dash,
)
# Pontos — equivalente a geom_point
scatter!(ax, x, y;
color = (cores[i], 0.85),
strokecolor = :white,
strokewidth = 0.8,
markersize = 11,
)
# Anotação com r e p-valor (equivalente a stat_cor do ggpubr)
# p-valor bilateral via distribuição t com n-2 graus de liberdade
n = length(x)
t_stat = r * sqrt(n - 2) / sqrt(1 - r^2)
pval = 2 * (1 - cdf(TDist(n - 2), abs(t_stat)))
pstr = pval < 0.001 ? "p < 0.001" : "p = $(round(pval; digits=3))"
text!(ax,
minimum(x) - 0.2, maximum(y) + 0.1;
text = "r = $(round(r; digits=3)), $pstr",
fontsize = 11,
color = :gray30,
align = (:left, :bottom),
)
end
# Ajuste de espaçamento entre subplots
colgap!(fig.layout, 18)
rowgap!(fig.layout, 14)
# ----------------------------------------------------------
# 5. Salvar a figura
# ----------------------------------------------------------
mkpath("assets/images")
save("assets/images/quarteto_anscombe_cairomakie.png", fig; px_per_unit = 2) # resolução 2×
println("Figura salva em: assets/images/quarteto_anscombe_cairomakie.png")
# Para visualizar interativamente no REPL:
# display(fig)Saída esperada no terminal
=== Quarteto de Anscombe — Estatísticas Descritivas ===
─── Exemplo 1 ───────────────────────────────
mean(x) = 9.0
mean(y) = 7.5009
var(x) = 11.0
var(y) = 4.1273
r Pearson = 0.8164
y = 0.5001x + 3.0001
─── Exemplo 2 ───────────────────────────────
mean(x) = 9.0
mean(y) = 7.5009
var(x) = 11.0
var(y) = 4.1276
r Pearson = 0.8162
y = 0.5x + 3.0009
─── Exemplo 3 ───────────────────────────────
mean(x) = 9.0
mean(y) = 7.5
var(x) = 11.0
var(y) = 4.1226
r Pearson = 0.8163
y = 0.4997x + 3.0025
─── Exemplo 4 ───────────────────────────────
mean(x) = 9.0
mean(y) = 7.5009
var(x) = 11.0
var(y) = 4.1232
r Pearson = 0.8165
y = 0.4999x + 3.0017
Figura salva em: assets/images/quarteto_anscombe_cairomakie.pngO arquivo gerado pelo script será:
assets/images/quarteto_anscombe_cairomakie.png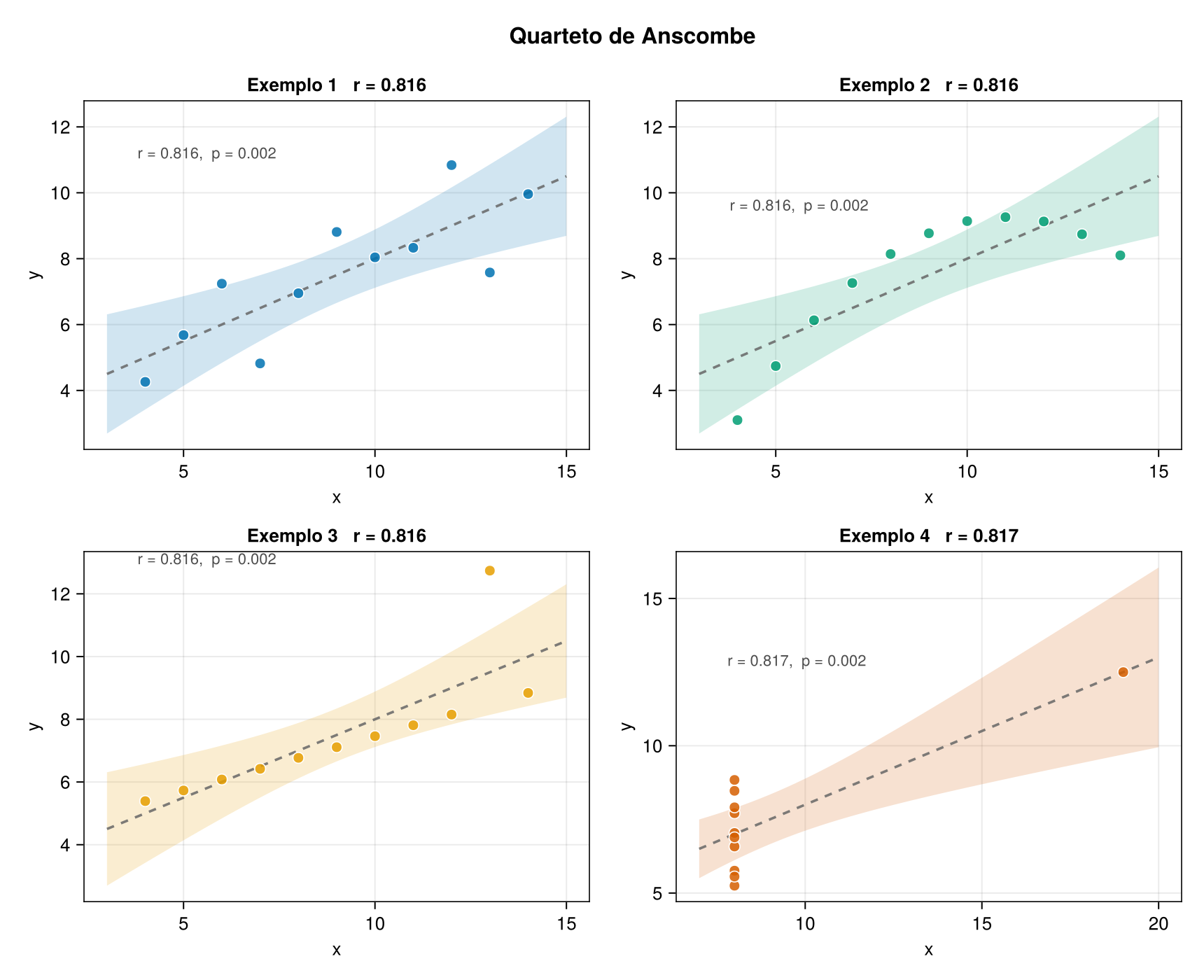
10. Como ler o gráfico gerado pelo código?
Quando a figura 2 × 2 é gerada, cada painel mostra:
| Elemento visual | Significado |
|---|---|
| Pontos | Observações reais de cada conjunto |
| Linha tracejada | Reta de regressão linear ajustada |
| Faixa sombreada | Intervalo de confiança pontual da regressão |
| Anotação $r$ | Correlação de Pearson calculada para o conjunto |
| Anotação do valor-p | Teste bilateral para correlação linear diferente de zero |
A parte mais interessante é comparar a linha tracejada com a nuvem de pontos.
No primeiro conjunto, a linha parece coerente.
No segundo, a linha ignora a curvatura.
No terceiro, a linha é afetada por um ponto atípico.
No quarto, a linha depende de um ponto com alta alavancagem.
A regressão linear não deve ser avaliada apenas pelos coeficientes. Ela precisa ser avaliada visualmente e também por diagnósticos do modelo.
11. O que esse exemplo ensina para projetos reais?
O Quarteto de Anscombe é pequeno, mas a lição vale para bases de dados reais.
Em pesquisas, relatórios, dashboards, artigos e análises operacionais, é comum resumir tudo com médias, desvios padrão, correlações e coeficientes de regressão.
Essas medidas são úteis, mas não substituem a inspeção visual.
Antes de concluir
Faça gráficos de dispersão.
Observe padrões não lineares.
Procure pontos discrepantes.
Verifique agrupamentos.
Antes de modelar
Cheque se a relação parece linear.
Investigue observações influentes.
Analise resíduos.
Não trate correlação como causalidade.
Uma análise estatística madura geralmente alterna entre dois movimentos:
\[\text{resumir numericamente} \quad \longleftrightarrow \quad \text{visualizar graficamente}\]Use tabelas para resumir. Use gráficos para investigar. Use modelos para formalizar. Nenhuma dessas etapas substitui totalmente as outras.
12. Erros comuns ao interpretar o Quarteto de Anscombe
Erro 1: achar que correlação alta significa relação linear bem comportada
A correlação de Pearson mede associação linear, mas pode ser alta em situações onde há curvatura, ponto influente ou estrutura artificial nos dados.
Erro 2: confiar na reta sem olhar os pontos
Uma reta de regressão sempre pode ser ajustada quando há variação em $x$, mas isso não significa que ela seja uma boa descrição da relação.
Erro 3: ignorar pontos influentes
Um único ponto pode alterar muito a inclinação, o intercepto e a correlação.
Erro 4: usar apenas tabelas em relatórios analíticos
Tabelas são úteis, mas podem esconder padrões que aparecem imediatamente em gráficos.
Quando uma análise depende de relações entre variáveis, gráficos de dispersão não são opcionais. Eles são parte do diagnóstico estatístico.
13. Conclusão
O Quarteto de Anscombe é um exemplo clássico porque desmonta uma ilusão comum: a ideia de que bons resumos numéricos bastam para entender os dados.
Os quatro conjuntos têm médias, variâncias, correlações e retas de regressão praticamente iguais.
Ainda assim, cada gráfico revela uma história diferente.
Isso mostra que a Estatística não deve ser feita apenas com fórmulas ou tabelas. Ela também precisa de visualização, contexto e julgamento crítico.
O Quarteto de Anscombe mostra que estatísticas resumidas podem parecer iguais, mesmo quando a estrutura real dos dados é completamente diferente.
Referências
As explicações deste post foram organizadas a partir do artigo original de Anscombe, de materiais sobre visualização estatística e da documentação oficial dos pacotes Julia usados no código.
-
Anscombe, F. J. — Graphs in Statistical Analysis. The American Statistician, 27(1), 17–21, 1973. DOI: 10.1080/00031305.1973.10478966.
https://www.tandfonline.com/doi/abs/10.1080/00031305.1973.10478966 -
JSTOR — Registro do artigo Graphs in Statistical Analysis, com DOI 10.2307/2682899.
https://www.jstor.org/stable/i326377 -
Matejka, J.; Fitzmaurice, G. — Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing. CHI 2017.
https://dl.acm.org/doi/10.1145/3025453.3025912 -
Autodesk Research — Same Stats, Different Graphs.
https://www.research.autodesk.com/publications/same-stats-different-graphs/ -
Julia — Statistics Standard Library: documentação oficial de funções como
mean,var,stde outras funções estatísticas básicas.
https://docs.julialang.org/en/v1/stdlib/Statistics/ -
Makie.jl — CairoMakie: documentação oficial do backend usado para gerar gráficos estáticos em Julia.
https://docs.makie.org/stable/documentation/backends/cairomakie/ -
Distributions.jl — documentação oficial do pacote usado no código para trabalhar com distribuições, incluindo a distribuição t de Student.
https://juliastats.org/Distributions.jl/

Comentários